")
When developing IoT, financial or industrial applications, the choice of a good time series database is most of the time a headache, choosing between the 30+ (and growing) list of time series vendors in the industry.
When choosing a time series database, it is best to know what they have to offer and how they can suit your needs.
Are you more about directly writing SQL, or do you prefer a brand new processing language for your time series? Are you concerned about cloud based solutions, or do you have your own integration solutions?
This article will help you benchmark your different options.
Here is the list of my best time series database to use in 2019.
1. InfluxDB
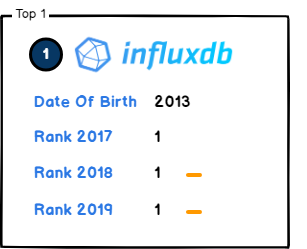
Built by InfluxData in 2013, InfluxDB is a completely open-source time series database working on all current operating systems. InfluxDB supports a very large set of programming languages (yes.. even Lisp and Clojure…). It is optimized for heavy writing load and works amazingly well with concurrency.
InfluxDB is schema-free : it is build on NoSQL flavors and allows for quick database schema modifications. Depending on what you are trying to build, this conceptual choice may or may not be adapted to your needs.
Why should you use InfluxDB?
- Play with it in 5 minutes
Five minutes is all it takes from the moment you download it until you are able to play with it. A good technical documentation makes it super easy to install, configure and launch InfluxDB. As a NoSQL-like database, you don’t have to setup your database in any ways : you insert your data and you are good to go.
- Integrated TICK stack
InfluxDB is part of the TICK stack : Telegraf, InfluxDB, Chronograf and Kapacitor. InfluxData provides, out of the box, a visualization tool (that can be compared to Grafana), a data processing engine that binds directly with InfluxDB, and a set of more than 50+ agents that can collect real-time metrics for a lot of different data sources.
Now let’s be fair.
InfluxDB is most of the time used with Grafana. Chronograf is not (at the moment) as good as Grafana, but InfluxData is trying to turn the ship around. By building Flux, a new processing language, and integrating it directly with Chronograf, they might offer some very unique features to it in the next months.
Want to know more about the Flux language? I wrote an article about it :
https://medium.com/schkn/sql-is-dead-hail-to-flux-8e8498756049
InfluxDB Website — influxdata.com
2. TimescaleDB

Ranked n°15 last year, TimescaleDB is making huge progress in the rankings this year.
Why?
Well if you ask me, they provide a very solid and scalable alternative to InfluxDB. TimescaleDB is also open-sourced and based on SQL premises. They also provide a very large set of supported programming languages (incl. Java and Python) for your applications to integrate directly with it.
TimescaleDB is directly tied with PostgresSQL as it scales the famous relational database to offer a unique set of time series related operations (such as fast ingest).
Why should you use TimescaleDB?
- SQL support :
One of the greatest assets of TimescaleDB is the fact that it supports the SQL language natively and allows developers to quickly jump the train without having to learn any new language. It is of course a very nice aspect for developer productivity, as you can ensure that SQL-experienced developers in your team can be immediately effective with TimescaleDB.
- PostgresSQL Integration :
The Guardian did a very nice article explaining on they went from MongoDB to PostgresSQL in the favor of scaling their architecture and encrypting their content at REST. As you can tell, big companies are relying on SQL-constraint systems (with a cloud architecture of course) to ensure system reliability and accessibility. I believe that PostgresSQL will continue to grow, so will TimescaleDB. By belonging to the PostgresSQL ecosystem, TimescaleDB will inherit from all the tools and plugins developed by this huge community.
- A debatable better performance than InfluxDB
I must emphasize that this is a ‘debatable’ better performance as systems are pretty new to the market and they were not tested on all the different cases that the industry has to offer.
As a fair-minded writer, I must point out the fact that Matvey Arye wrote a very good article comparing Flux to SQL and in a way InfluxDB to TimescaleDB. His points about query optimization in particular should be read carefully and they provide a very solid explanation on why they could be more performant (at least in theory).
Matvey Arye article — SQL vs Flux
TimescaleDB Website — timescale.com
3. OpenTSDB
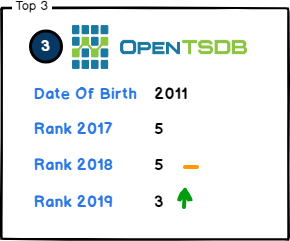
OpenTSDB has been running for quite more time than its competitors and is one of the first technologies to address the need to store time series data at a very large scale. OpenTSDB promises to be able to store hundreds of billions of data rows over distributed instances of TSD servers.
OpenTSDB is a schema free database built on Apache HBase. For those who don’t know, HBase is a non-relational management system written to handle big tables storage in an elegant and efficient way.
Why should you use OpenTSDB ?
- Performance!
Ted Dunning (Chief Application Architect at MapR) made a quite explicative talk about how time series database should be built and how horizontal arranging of time ranges could scale a DBMS up to 20 to 30 millions writes per second. This is a huge insertion rate considering a single InfluxDB node instance could insert up to one million writes per second.
You might want to give OpenTSDB a shot if you are dealing with such insertions rates in your system.
- Integration Ecosystem
Reading the documentation, OpenTSDB integrates with a fair amount of tools such as Cassandra, BigTable, CollectD, StatsD, Chef and even Puppet for deployment management.
Ted Dunning on Time Series Database Architecture
OpenTSDB Website — opentsdb.net
4. Graphite
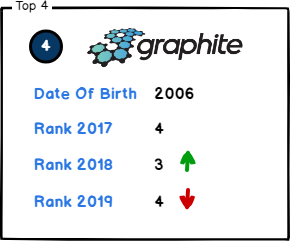
Graphite is a even more established and very widely used time series database system. Graphite is a powerful monitoring tool that store numeric time series data and display them on demand via its Graphite-web interface at a fair speed. Graphite is most of the time used as a system, network and application performance metric store. Big companies such as Booking.com, Reddit and GitHub use it on a daily basis to be able to easily detect outage on their architecture.
Why should you use Graphite?
- Graphite does a few things, but it does it well.
Graphite is built to deal with numeric data. As it can be a limitation in itself if you are not dealing with numeric data, Graphite provides out of the box a set of tools that makes it easy for developers to get started. Graphite Web provides a very nice interface for developers to monitor their application.
- A Good Integration Ecosystem
As OpenTSDB, Graphite connects with a lot of tools natively and makes it easy for developers to connect with their existing infrastructure. Graphite is able to easily connect with CollectD, sensu, Riemann, Windows Server, Logstash and many more.
Graphite Website — graphiteapp.org
X — Your Turn To Share!
Do you have experience with those time series databases? If so, which one would you recommend and why?
Also, if you find that some TSMS should be ranked higher or lower, feel free to give your own rankings in the comment section.
14 comments
[…] Source: devconnected.com […]
Url to guardian post please, thanks
Here’s the article Olga : https://www.theguardian.com/info/2018/nov/30/bye-bye-mongo-hello-postgres
What about Prometheus? I think it will be no. 1 because it’s default TSDB for Kubernetus
Hello Nikolay. Prometheus is indeed coming big and I believe it will be a major actor of the market in the next few months.
I’m preparing an article where Prometheus will be involved by the way. 🙂
Prometheus is not a time series database, it is a monitoring system. You cannot pusha data which is either late or in the future in Prometheus.
Sad to see Warp 10 is missing when it is fully open source, which is not the case of influxdb which has no open source cluster version, has a full fledged programming language for time series, with over 900 functions, compared to flux 20 or so, and has been used by OVH to store 500 million series with ingestion rates up to 120M per second.
Remember db engines ranking is based on popularity on the web, not quality or robustness. No sentiment analysis is performed for their ranking meaning that a system everyone ckmplains about will be better ranked than a solution running smoothly.
Hello Mathias,
Thank you for your insightful comment.
I do believe that there is a correlation between the hype and the actual effectiveness of a product in some cases.
I am also perfectly aware that no product is covering all the needs, and that it would be fanciful to design a product
in such a way that it is supposed to accomplish such a tremendous task.
Strategies differ but certain patterns are emerging from those developments :
– Promoting system connectivity by bringing tools to work together (Prometheus initiative with exporters for example)
– Bringing system reactivity by leveraging alert and analysis tools, targeting the BI and IoT industries. Examples may be Grafana, AlertManager and Kapacitor.
– Investing in a query language that abstracts data complexity ; you mentionned it with the Flux language. Another example is Timescale investing in
SQL and PostgresSQL, targeting developers already efficient with SQL.
System performance is an important factor. But as in every solution, designed by humans, for humans, I believe that non-quantitative factors (such as the way
the product is perceived) are equally important.
Nonetheless, curious developers can check Warp10. With the rise of the space industry, space and time become heavily correlated and Warp10
creates the link between the two.
Thank you again.
I’d recommend looking at VictoriaMetrics.
Why should you use VictoriaMetrics?
1. Because it is the most cost-effective TSDB on the market. It requires less hardware – CPU, RAM, storage – for the same amount of time series data comparing to competitors. See the following articles for details:
– https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
– https://medium.com/@valyala/insert-benchmarks-with-inch-influxdb-vs-victoriametrics-e31a41ae2893
2. Because it seamlessly integrates with Prometheus+Grafana stack. It natively supports Prometheus query language – PromQL.
3. Because it is easy to run, configure and operate. See https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/Single-server-VictoriaMetrics
Great write-up. What are your thoughts on Amazon announcing Timestream, as a new AWS database offering for tsd?
Did you have a look on warp10 ? The Geo Time series ? We (at Clever Cloud) using it at dozens of gigabyte per hours with a lot of analysis running on top of the cluster. It worth it https://warp10.io/
I guess it’s implicit that this list is open source only? KDB+ is a better database than those on this list by all technical metrics. From a speed perspective, the only thing that can compete with KDB are distributed GPU databases.
Maybe it would be a good idea to mention ClickHouse in article. ClickHouse is not just TSDB and easily can be used instead of it. There are some benchmarks TimescaleDB and InfluxDB: https://www.altinity.com/blog/clickhouse-for-time-series , https://medium.com/@AltinityDB/clickhouse-for-time-series-scalability-benchmarks-e181132a895b
What about Uber’s open-sourced TSDB?
https://eng.uber.com/m3/
We are using TimeScaleDB and love it. We used to use influx, but moved to TimeScale for the SQL support and JOINS (remember them? Useful actually…) . We are also trialing TimeStream at the moment.
Another one to add to the list that looks very interesting is Apache Druid – https://druid.apache.org/